
At the heart of any robust AI platform lies a critical component: the AI gateway. It's the central nervous system that routes requests, manages diverse model integrations, and ensures seamless operation. But with a growing ecosystem of AI models (OpenAI, Anthropic, and more), SDKs, and runtime environments (Node.js, Bun, Python), how do we guarantee everything works flawlessly, all the time?
Enter Collider: our in-house, comprehensive testing framework designed to rigorously validate all key functionalities across our platform, with particular focus on our AI gateway's complex model integrations. Collider isn't just another test suite; it's an intelligent system that automates execution, analyzes results with AI, and even helps us triage and fix issues faster.
The Challenge: Taming the Complexity of LLM Integrations
Testing a modern AI gateway presents unique challenges:
- Diverse Ecosystem: We support a multitude of models, each with its own API, quirks, and update cycles.
- Multiple Runtimes & SDKs: Our services need to perform consistently across different environments like Node.js and Bun ( each potentially using different SDKs.
- Rapid Evolution: The AI landscape changes daily. Models get deprecated, new ones emerge, and API contracts shift. Staying on top requires constant vigilance.
Manual testing quickly becomes untenable. We needed a solution that was automated, scalable, and intelligent.
How Collider Works: An Orchestrated Approach to Quality
Collider employs a multi-stage process to ensure our AI gateway is always in top shape:
-
Centralized Orchestration & Distributed Execution:
- The process begins with a central orchestrator agent. When a test cycle is initiated, it generates a unique
runIdto track all subsequent operations for that specific run. - This orchestrator then fans out test execution requests to a series of specialized agents. Each agent is configured to test specific aspects of our gateway, such as a particular model SDK within a specific runtime environment (e.g., Node.js, Bun).
- These tests run in parallel, significantly speeding up the feedback loop.
- The process begins with a central orchestrator agent. When a test cycle is initiated, it generates a unique
-
Data Persistence & Initial Collection:
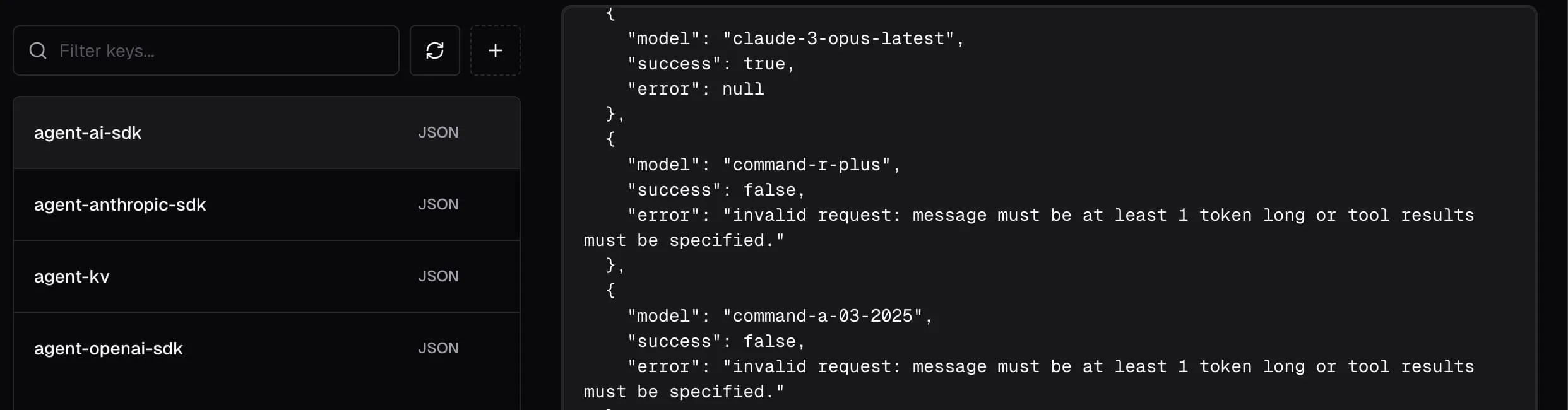
- As agents complete their tests (e.g., making calls to various model endpoints, testing key-value store functionality), they record their results.
- These results, including status (success/error), error messages, model details, and the
runId, are persisted into our Neon PostgreSQL database, adhering to a standardized schema.
-
AI-Powered Report Generation (GPT-4o):
- Once all tests are complete and data is in the database, we query for all errors associated with the current
runId. - This raw JSON array of error logs, along with a carefully crafted system prompt, is then fed to OpenAI's
gpt-4omodel. - The system prompt instructs
gpt-4oto transform the error data into a human-readable Markdown report. This report includes:- A summary of total tests vs. errors.
- A table titled "🧠 Agent SDK Model Tests" detailing failures for SDK-based model integrations.
- A separate table "🧪 Key-Value Store Tests" for issues related to our key-value store agent.
- Columns include Project, Agent, Model (if applicable), Language, Runtime, Status, Error Message, and the overarching Test Run Id.
- Once all tests are complete and data is in the database, we query for all errors associated with the current
-
Automated Error Triage (Devin API):
- If the
gpt-4oreport indicates any errors, we take automation a step further. The generated Markdown report is passed to our Devin API integration. - A specialized prompt guides this AI to:
- Triage all errors by grouping them into meaningful categories (e.g., "invalid API key," "model deprecated," "wrong endpoint usage").
- For each category, summarize the root cause.
- Propose concrete next steps to fix the issue.
- Crucially, if tests are broken due to outdated configurations or incorrect test expectations (like a deprecated model), Devin is instructed to attempt to open a pull request to the test repository to fix them, making minimal, targeted changes.
- If the
-
Notification & Accessibility:
- The final
gpt-4o-generated Markdown report is stored in a key-value store for 7 days, making it accessible via a unique URL. - A notification is then sent to our designated Slack channel. This message includes:
- An immediate visual cue (🟥 for errors, ✅ for success).
- A count of errors vs. total tests.
- A direct link to the full test results report.
- If errors occurred, a link to the Devin session where triage and potential fixes are being handled.
- The
testResultId(date +runId) and the rawrunIdfor easy tracking.
- The final
Why Collider Matters
Collider is more than just a testing tool; it's a critical piece of our engineering quality and velocity:
- Comprehensive Coverage: Ensures that our integrations with numerous AI models across different runtimes are functioning correctly.
- Early Detection: Catches regressions or issues introduced by upstream model changes or internal code modifications quickly, complementing our built-in observability tooling.
- Intelligent Analysis: Moves beyond simple pass/fail. GPT-4o provides structured, readable reports, and Devin offers actionable insights and even automated fix suggestions.
- Reduced Mean Time to Resolution (MTTR): By automatically triaging errors and suggesting fixes, Collider significantly speeds up the debugging process.
- Developer Productivity: Frees up engineers from manual testing and allows them to focus on building new features.
By investing in intelligent testing infrastructure like Collider, we're ensuring that our AI gateway remains reliable, performant, and ready to adapt to the ever-evolving world of artificial intelligence. It's a testament to our commitment to delivering high-quality AI-powered experiences.